The meaning of the mean¶
The mean is an interesting value.
In this notebook, we fetch an example sequence of numbers, with a distribution that is far from the standard bell-curve distribution. We look at the properties of the mean as a predictor of the whole distribution.
First we load our usual libraries.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Make plots look a little bit more fancy
plt.style.use('fivethirtyeight')
# Print to 2 decimal places, show tiny values as 0
np.set_printoptions(precision=2, suppress=True)
We need Pandas to load the gender data that we first saw in the data frame introduction.
import pandas as pd
The dataset is gender_stats.csv.
This contains some World Bank statistics for each country on health and
economic factors related to gender equality. See the data file page for more detail.
# Load the data file
gender_data = pd.read_csv('gender_stats.csv')
In this case, we are only interested in the data for the Maternal Mortality
Ratio mat_mort_ratio.
mat_mort_ratio = gender_data['mat_mort_ratio']
There are many NaN values in mat_mort_ratio. For simplicity, we drop
these.
mat_mort_valid = mat_mort_ratio.dropna()
mat_mort_valid is a still a Pandas Series:
type(mat_mort_valid)
pandas.core.series.Series
Again, to make things a bit simpler, we convert this Series to an ordinary Numpy array:
mm_arr = np.array(mat_mort_valid)
The values for mm_arr are very far from a standard bell-curve or normal distribution.
plt.hist(mm_arr);
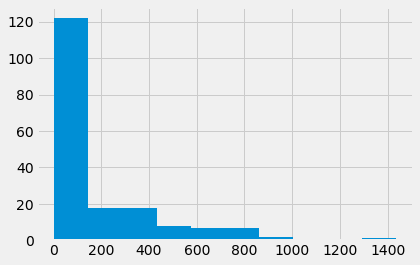
We are interested in the mean.
mm_mean = np.mean(mm_arr)
mm_mean
175.724043715847
As you remember, we get the mean by adding up all the values, and then dividing by the number of values, often written as \(n\).
np.sum(mm_arr) / len(mm_arr)
175.724043715847
Now let’s consider the following situation.
I have all the values on my computer.
You don’t have any of the values.
I want to give you one value, that will do the best possible job of predicting the values. Call this the predictor.
Then I give you the values from the distribution one by one. You see how good your prediction is, by subtracting the predictor from the value I just gave you. That is your prediction error for that value.
One value I could give you as a predictor, is the mean.
Is that a good value to give you?
Let’s start by shuffling up the values, ready to give you, one by one.
# Not really necessary, but still.
mm_shuffled = np.random.permutation(mm_arr)
I give you the mean, as a predictor.
Then I pass you the first value. You subtract your predictor, to get the prediction error.
prediction_error_0 = mm_shuffled[0] - mm_mean
prediction_error_0
-152.724043715847
We do the same for the second value:
prediction_error_1 = mm_shuffled[1] - mm_mean
prediction_error_1
-36.97404371584699
To cut to the end, let’s do all the values at once:
# Calculate all the prediction errors
prediction_errors = mm_shuffled - mm_mean
# Show the first 10
prediction_errors[:10]
array([-152.72, -36.97, -97.47, -150.47, -166.72, 502.53, 224.78,
-16.22, -161.72, -113.72])
What do the prediction errors look like?
plt.hist(prediction_errors);
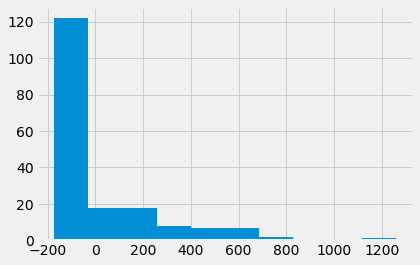
Notice the by-eye center of this distribution of prediction errors.
Let’s add up all the prediction errors:
np.sum(prediction_errors)
1.8189894035458565e-12
The prediction errors add up to (very nearly) 0. This is a property of the mean. The deviations from the mean sum to zero.
In fact, it is not very hard to show that the deviations must sum to zero.
Here was our mean.
mm_mean
175.724043715847
Another prediction we might be interested in, is one that gives us the smallest squared difference from the actual values.
Here are the squared differences from the mean.
# Squared prediction errors, for the mean
squared_pes = prediction_errors ** 2
# Show the first ten
squared_pes[:10]
array([ 23324.63, 1367.08, 9501.19, 22642.44, 27796.91, 252532.34,
50524.23, 263.22, 26154.67, 12933.16])
With a good prediction, we might want these squared prediction errors to be small. We can see how small these are by adding them all up. This gives us the “sum of squares”.
sos = np.sum(squared_pes)
sos
10611707.56420765
That is the sum of squared prediction errors that the mean gives us. Could some other value give us a better (lower) sum of squared prediction error?
Let’s try lots of predictors, to see which gives us the smallest squared prediction error.
# Try lots of values between 150 and 210
predictors = np.arange(150, 210, 0.1)
# First 10
predictors[:10]
array([150. , 150.1, 150.2, 150.3, 150.4, 150.5, 150.6, 150.7, 150.8,
150.9])
We make a function that accepts the values, and the predictor as arguments, and returns the sum of squares of the prediction errors:
def sum_of_squares(vals, predictor):
pred_errs = vals - predictor
sq_pred_errs = pred_errs ** 2
return np.sum(sq_pred_errs)
We confirm that this gives us the value we saw before, when we use the mean as a predictor:
sum_of_squares(mm_arr, mm_mean)
10611707.56420765
Here’s what we get if we use the first predictor value:
sum_of_squares(mm_arr, predictors[0])
10732803.5
Now we try all the predictor values, to see which value gives us the lowest sum of squared errors.
# How many predictors do we have to try?
n_predictors = len(predictors)
n_predictors
600
# An array to store the sum of squares values for each predictor
sos_for_predictors = np.ones(n_predictors)
We calculate all the sums of squares:
for i in np.arange(n_predictors):
predictor = predictors[i]
sos = sum_of_squares(mm_arr, predictor)
sos_for_predictors[i] = sos
Which predictor is giving us the lowest value for the sum of squares?
plt.plot(predictors, sos_for_predictors)
plt.xlabel('Predictor')
plt.ylabel('Sum of squares');
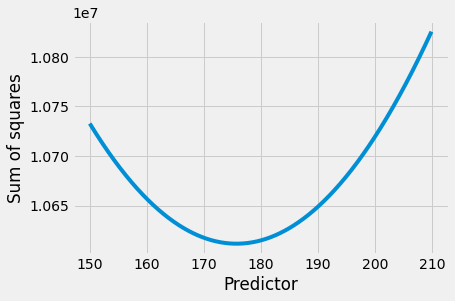
The smallest value we found for the sum of squares was:
np.min(sos_for_predictors)
10611707.67
In fact, the value for the mean is even lower:
sum_of_squares(mm_arr, mm_mean)
10611707.56420765
We would have to use some fairly simple calculus and algebra to show this, but the mean has to give the lowest sum of squares error.
Put another way, the mean minimizes:
the sum of the errors;
the sum of squared errors.