Nearest neighbors¶
# HIDDEN
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import pandas as pd
# HIDDEN
def standard_units(x):
return (x - np.mean(x))/np.std(x)
# HIDDEN
def distance(point1, point2):
"""The distance between two arrays of numbers."""
return np.sqrt(np.sum((point1 - point2)**2))
def all_distances(training, point):
"""The distance between p (an array of numbers) and the numbers in row i of attribute_table."""
attributes = training.drop(columns='Class')
def distance_from_point(row):
return distance(point, np.array(row))
return attributes.apply(distance_from_point, axis=1)
def table_with_distances(training, point):
"""A copy of the training table with the distance from each row to array p."""
out = training.copy()
out['Distance'] = all_distances(training, point)
return out
def closest(training, point, k):
"""A table containing the k closest rows in the training table to array p."""
with_dists = table_with_distances(training, point)
sorted_by_distance = with_dists.sort_values('Distance')
topk = sorted_by_distance.iloc[:k]
return topk
def majority(topkclasses):
"""1 if the majority of the class values are 1s, 0 otherwise."""
ones = np.count_nonzero(topkclasses == 1)
zeros = np.count_nonzero(topkclasses == 0)
if ones > zeros:
return 1
else:
return 0
def classify(training, p, k):
"""Classify an example with attributes p using k-nearest neighbor classification with the given training table."""
closestk = closest(training, p, k)
return majority(closestk['Class'])
In this section we’ll develop the nearest neighbor method of classification. Just focus on the ideas for now and don’t worry if some of the code is mysterious. Later in the chapter we’ll see how to organize our ideas into code that performs the classification.
Chronic kidney disease¶
Let’s work through an example. We’re going to work with a data set that was collected to help doctors diagnose chronic kidney disease (CKD). Each row in the data set represents a single patient who was treated in the past and whose diagnosis is known. For each patient, we have a bunch of measurements from a blood test. We’d like to find which measurements are most useful for diagnosing CKD, and develop a way to classify future patients as “has CKD” or “doesn’t have CKD” based on their blood test results.
If you are running on your laptop, you should download the
ckd.csv file to the same
directory as this notebook.
ckd_full = pd.read_csv('ckd.csv')
ckd_full.head()
| Age | Blood Pressure | Specific Gravity | Albumin | Sugar | Red Blood Cells | Pus Cell | Pus Cell clumps | Bacteria | Blood Glucose Random | ... | Packed Cell Volume | White Blood Cell Count | Red Blood Cell Count | Hypertension | Diabetes Mellitus | Coronary Artery Disease | Appetite | Pedal Edema | Anemia | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 48 | 70 | 1.005 | 4 | 0 | normal | abnormal | present | notpresent | 117 | ... | 32 | 6700 | 3.9 | yes | no | no | poor | yes | yes | 1 |
| 1 | 53 | 90 | 1.020 | 2 | 0 | abnormal | abnormal | present | notpresent | 70 | ... | 29 | 12100 | 3.7 | yes | yes | no | poor | no | yes | 1 |
| 2 | 63 | 70 | 1.010 | 3 | 0 | abnormal | abnormal | present | notpresent | 380 | ... | 32 | 4500 | 3.8 | yes | yes | no | poor | yes | no | 1 |
| 3 | 68 | 80 | 1.010 | 3 | 2 | normal | abnormal | present | present | 157 | ... | 16 | 11000 | 2.6 | yes | yes | yes | poor | yes | no | 1 |
| 4 | 61 | 80 | 1.015 | 2 | 0 | abnormal | abnormal | notpresent | notpresent | 173 | ... | 24 | 9200 | 3.2 | yes | yes | yes | poor | yes | yes | 1 |
5 rows × 25 columns
Some of the variables are categorical (words like “abnormal”), and some quantitative. The quantitative variables all have different scales. We’re going to want to make comparisons and estimate distances, often by eye, so let’s select just a few of the variables and work in standard units. Then we won’t have to worry about the scale of each of the different variables.
ckd = pd.DataFrame()
ckd['Hemoglobin'] = standard_units(ckd_full['Hemoglobin'])
ckd['Glucose'] = standard_units(ckd_full['Blood Glucose Random'])
ckd['WBC'] = standard_units(ckd_full['White Blood Cell Count'])
ckd['Class'] = ckd_full['Class']
ckd.head()
| Hemoglobin | Glucose | WBC | Class | |
|---|---|---|---|---|
| 0 | -0.865744 | -0.221549 | -0.569768 | 1 |
| 1 | -1.457446 | -0.947597 | 1.162684 | 1 |
| 2 | -1.004968 | 3.841231 | -1.275582 | 1 |
| 3 | -2.814879 | 0.396364 | 0.809777 | 1 |
| 4 | -2.083954 | 0.643529 | 0.232293 | 1 |
Let’s look at two columns in particular: the hemoglobin level (in the patient’s blood), and the blood glucose level (at a random time in the day; without fasting specially for the blood test).
We’ll draw a scatter plot to visualize the relation between the two variables. Blue dots are patients with CKD; gold dots are patients without CKD. What kind of medical test results seem to indicate CKD?
ckd['Color'] = 'darkblue'
ckd.loc[ckd['Class'] == 0, 'Color'] = 'gold'
ckd.head()
| Hemoglobin | Glucose | WBC | Class | Color | |
|---|---|---|---|---|---|
| 0 | -0.865744 | -0.221549 | -0.569768 | 1 | darkblue |
| 1 | -1.457446 | -0.947597 | 1.162684 | 1 | darkblue |
| 2 | -1.004968 | 3.841231 | -1.275582 | 1 | darkblue |
| 3 | -2.814879 | 0.396364 | 0.809777 | 1 | darkblue |
| 4 | -2.083954 | 0.643529 | 0.232293 | 1 | darkblue |
ckd.plot.scatter('Hemoglobin', 'Glucose', c=ckd['Color']);
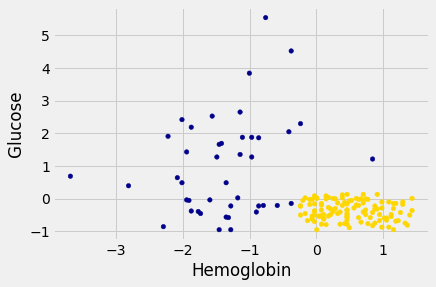
Suppose Alice is a new patient who is not in the data set. If I tell you Alice’s hemoglobin level and blood glucose level, could you predict whether she has CKD? It sure looks like it! You can see a very clear pattern here: points in the lower-right tend to represent people who don’t have CKD, and the rest tend to be folks with CKD. To a human, the pattern is obvious. But how can we program a computer to automatically detect patterns such as this one?
A Nearest Neighbor Classifier¶
There are lots of kinds of patterns one might look for, and lots of algorithms for classification. But I’m going to tell you about one that turns out to be surprisingly effective. It is called nearest neighbor classification. Here’s the idea. If we have Alice’s hemoglobin and glucose numbers, we can put her somewhere on this scatterplot; the hemoglobin is her x-coordinate, and the glucose is her y-coordinate. Now, to predict whether she has CKD or not, we find the nearest point in the scatterplot and check whether it is blue or gold; we predict that Alice should receive the same diagnosis as that patient.
In other words, to classify Alice as CKD or not, we find the patient in the training set who is “nearest” to Alice, and then use that patient’s diagnosis as our prediction for Alice. The intuition is that if two points are near each other in the scatterplot, then the corresponding measurements are pretty similar, so we might expect them to receive the same diagnosis (more likely than not). We don’t know Alice’s diagnosis, but we do know the diagnosis of all the patients in the training set, so we find the patient in the training set who is most similar to Alice, and use that patient’s diagnosis to predict Alice’s diagnosis.
In the graph below, the red dot represents Alice. It is joined with a black line to the point that is nearest to it – its nearest neighbor in the training set. The figure is drawn by a function called show_closest. It takes an array that represents the \(x\) and \(y\) coordinates of Alice’s point. Vary those to see how the closest point changes! Note especially when the closest point is blue and when it is gold.
# HIDDEN
def show_closest(point):
"""point = array([x,y])
gives the coordinates of a new point
shown in red"""
HemoGl = ckd[['Hemoglobin', 'Glucose', 'Class']]
t = closest(HemoGl, point, 1)
x_closest = float(t['Hemoglobin'])
y_closest = float(t['Glucose'])
ckd.plot.scatter('Hemoglobin', 'Glucose', c=ckd['Color'])
plt.scatter(point[0], point[1], color='red', s=30)
plt.plot([point[0], x_closest],
[point[1], y_closest],
color='k', lw=2);
# In this example, Alice's Hemoglobin attribute is 0 and her Glucose is 1.5.
alice = np.array([0, 1.5])
show_closest(alice)
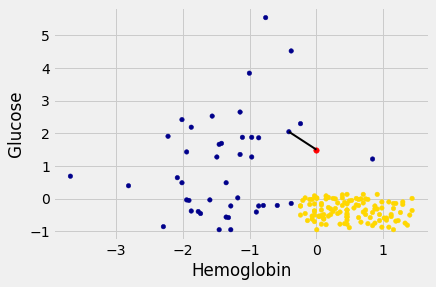
Thus our nearest neighbor classifier works like this:
Find the point in the training set that is nearest to the new point.
If that nearest point is a “CKD” point, classify the new point as “CKD”. If the nearest point is a “not CKD” point, classify the new point as “not CKD”.
The scatterplot suggests that this nearest neighbor classifier should be pretty accurate. Points in the lower-right will tend to receive a “no CKD” diagnosis, as their nearest neighbor will be a gold point. The rest of the points will tend to receive a “CKD” diagnosis, as their nearest neighbor will be a blue point. So the nearest neighbor strategy seems to capture our intuition pretty well, for this example.
Decision boundary¶
Sometimes a helpful way to visualize a classifier is to map out the kinds of attributes where the classifier would predict ‘CKD’, and the kinds where it would predict ‘not CKD’. We end up with some boundary between the two, where points on one side of the boundary will be classified ‘CKD’ and points on the other side will be classified ‘not CKD’. This boundary is called the decision boundary. Each different classifier will have a different decision boundary; the decision boundary is just a way to visualize what criteria the classifier is using to classify points.
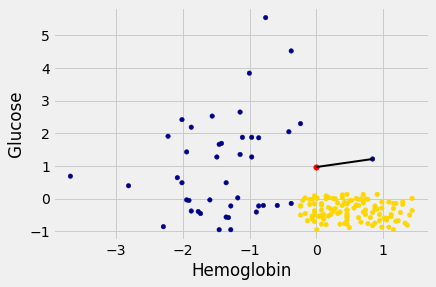
For example, suppose the coordinates of Alice’s point are (0, 1.5). Notice that the nearest neighbor is blue. Now try reducing the height (the \(y\)-coordinate) of the point. You’ll see that at around \(y = 0.95\) the nearest neighbor turns from blue to gold.
alice = np.array([0, 0.97])
show_closest(alice)
Here are hundreds of new unclassified points, all in red.
# HIDDEN
# Values for x and y coordinates
x_vals = np.arange(-2, 2.1, 0.1)
n_x = len(x_vals)
y_vals = np.arange(-2, 2.1, 0.1)
n_y = len(y_vals)
# Make the vector of x and corresponding y coordinates to cover
# the whole 2D grid. For the expert way, see Numpy meshgrid.
# Repeat each value of the x coordinate n_y times
x_coords = np.repeat(x_vals, n_y)
# Repeat the whole y_vals vector n_x times
y_coords = np.tile(y_vals, n_x)
# Put these into a data frame for convenience
test_grid = pd.DataFrame()
test_grid['Hemoglobin'] = x_coords
test_grid['Glucose'] = y_coords
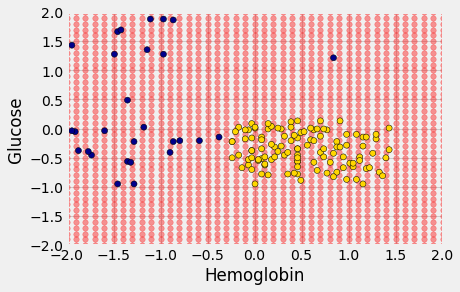
Each of the red points has a nearest neighbor in the training set (the same blue and gold points as before). For some red points you can easily tell whether the nearest neighbor is blue or gold. For others, it’s a little more tricky to make the decision by eye. Those are the points near the decision boundary.
But the computer can easily determine the nearest neighbor of each point. So let’s get it to apply our nearest neighbor classifier to each of the red points:
For each red point, it must find the closest point in the training set; it must then change the color of the red point to become the color of the nearest neighbor.
The resulting graph shows which points will get classified as ‘CKD’ (all the blue ones), and which as ‘not CKD’ (all the gold ones).
# HIDDEN
def classify_grid(training, test, k):
n_test = len(test)
c = np.zeros(n_test)
for i in range(n_test):
# Run the classifier on the ith patient in the test set
c[i] = classify(training, np.array(test.iloc[i]), k)
return c
# HIDDEN
c = classify_grid(ckd[['Hemoglobin', 'Glucose', 'Class']],
test_grid,
1)
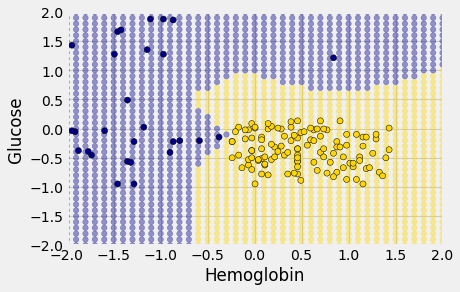
The decision boundary is where the classifier switches from turning the red points blue to turning them gold.
k-Nearest Neighbors¶
However, the separation between the two classes won’t always be quite so clean. For instance, suppose that instead of hemoglobin levels we were to look at white blood cell count. Look at what happens:
ckd.plot.scatter('WBC',
'Glucose',
c=ckd['Color'])
<AxesSubplot:xlabel='WBC', ylabel='Glucose'>
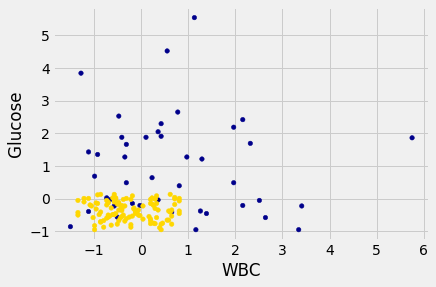
As you can see, non-CKD individuals are all clustered in the lower-left. Most of the patients with CKD are above or to the right of that cluster… but not all. There are some patients with CKD who are in the lower left of the above figure (as indicated by the handful of blue dots scattered among the gold cluster). What this means is that you can’t tell for certain whether someone has CKD from just these two blood test measurements.
If we are given Alice’s glucose level and white blood cell count, can we predict whether she has CKD? Yes, we can make a prediction, but we shouldn’t expect it to be 100% accurate. Intuitively, it seems like there’s a natural strategy for predicting: plot where Alice lands in the scatter plot; if she is in the lower-left, predict that she doesn’t have CKD, otherwise predict she has CKD.
This isn’t perfect – our predictions will sometimes be wrong. (Take a minute and think it through: for which patients will it make a mistake?) As the scatterplot above indicates, sometimes people with CKD have glucose and white blood cell levels that look identical to those of someone without CKD, so any classifier is inevitably going to make the wrong prediction for them.
Can we automate this on a computer? Well, the nearest neighbor classifier would be a reasonable choice here too. Take a minute and think it through: how will its predictions compare to those from the intuitive strategy above? When will they differ?
Its predictions will be pretty similar to our intuitive strategy, but occasionally it will make a different prediction. In particular, if Alice’s blood test results happen to put her right near one of the blue dots in the lower-left, the intuitive strategy would predict ‘not CKD’, whereas the nearest neighbor classifier will predict ‘CKD’.
There is a simple generalization of the nearest neighbor classifier that fixes this anomaly. It is called the k-nearest neighbor classifier. To predict Alice’s diagnosis, rather than looking at just the one neighbor closest to her, we can look at the 3 points that are closest to her, and use the diagnosis for each of those 3 points to predict Alice’s diagnosis. In particular, we’ll use the majority value among those 3 diagnoses as our prediction for Alice’s diagnosis. Of course, there’s nothing special about the number 3: we could use 4, or 5, or more. (It’s often convenient to pick an odd number, so that we don’t have to deal with ties.) In general, we pick a number \(k\), and our predicted diagnosis for Alice is based on the \(k\) patients in the training set who are closest to Alice. Intuitively, these are the \(k\) patients whose blood test results were most similar to Alice, so it seems reasonable to use their diagnoses to predict Alice’s diagnosis.
The \(k\)-nearest neighbor classifier will now behave just like our intuitive strategy above.
Note
This page has content from the Nearest_Neighbors notebook of an older version of the UC Berkeley data science course. See the Berkeley course section of the license file.