Where are the Brexiteers?¶
See: Where are the Brexiteers? for background.
We are going to load this data using the Pandas package for data analysis.
Pandas is a large, powerful package that is very popular for data analysis. You might want to read the Pandas documentation and you will find lots of help with Google searches and the StackOverflow question answer site.
First we import the package, so it is ready to use. Actually we will import it, and also give it a nice short name so we do not have to do much typing to use the package:
>>> import pandas
The data file that you just downloaded should be called
audit_of_political_engagement_14_2017.tab. We load the data file into
memory with Pandas:
>>> audit_data = pandas.read_table('audit_of_political_engagement_14_2017.tab')
We now have something called a “data frame”:
>>> type(audit_data)
<class 'pandas.core.frame.DataFrame'>
The DataFrame type of object is a table, rather like a spreadsheet, where
there is one row per person surveyed, and one column for each question in the
survey. The columns have helpful names that you can read about in the data
dictionary:
>>> audit_data
cu041 cu042 cu043 cu044 cu045 ...
0 0 0 0 0 1 ...
1 0 0 0 0 0 ...
2 0 0 0 0 1 ...
3 0 0 0 0 1 ...
4 0 0 0 1 1 ...
5 1 1 0 0 0 ...
...
[1771 rows x 370 columns]
The data frame has columns for all the questions listed in the data dictionary:
>>> audit_data.columns
Index(['cu041', 'cu042', 'cu043', 'cu044', 'cu045', 'cu046', 'cu047', 'cu048',
'cu049', 'cu0410',
...
'intten', 'cx_971_980', 'serial', 'week', 'wts', 'numage', 'weight0',
'sgrade_grp', 'age_grp', 'region2'],
dtype='object', length=370)
To reduce clutter, we first make a new data frame that just has the two questions we are interested in:
>>> # Select the age and Brexit vote questions only
>>> brexit_age = audit_data[['numage', 'cut15']]
>>> brexit_age
numage cut15
0 37 1
1 55 1
2 71 2
3 37 1
4 42 1
5 0 1
...
[1771 rows x 2 columns]
The variable name cut15 is not very memorable, and we care about
memorable, because good names help to keep our ideas clear as we are working.
We rename the columns from their original names to more memorable ones:
>>> # Rename the columns to be more memorable
>>> brexit_age.columns = ['age', 'brexit']
>>> brexit_age
age brexit
0 37 1
1 55 1
2 71 2
3 37 1
4 42 1
5 0 1
...
[1771 rows x 2 columns]
Wait — there’s something odd in those numbers.
We were lucky to spot that, but in any case, we want to check our data before we continue. The first thing we do is make a histogram of the ages.
To do this we first need to load the standard Python plotting library, Matplotlib.
Hint
If running in the IPython console, consider running %matplotlib to enable
interactive plots. If running in the Jupyter Notebook, use %matplotlib
inline.
Remember that we did an “import” for the Pandas package above. Now we import
part of matplotlib.
>>> import matplotlib.pyplot
What type of thing is matplotlib.pyplot?
>>> type(matplotlib.pyplot)
<class 'module'>
We use the hist function in matplotlib.pyplot to plot a histogram of
the respondents’ ages:
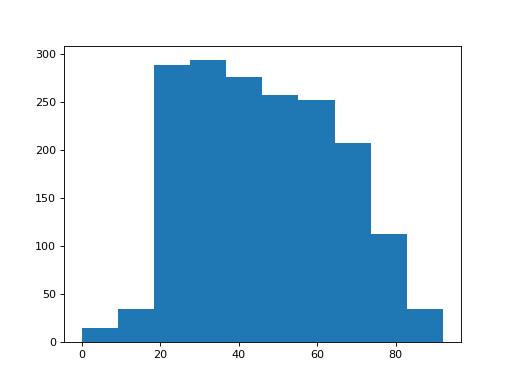
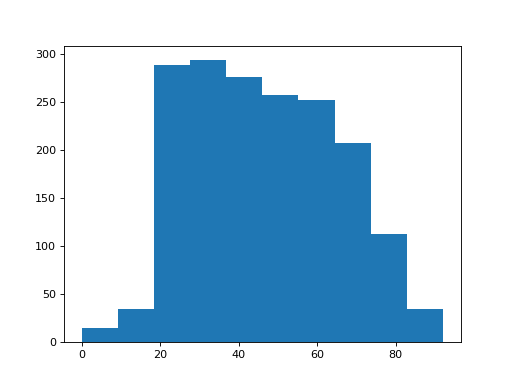
>>> matplotlib.pyplot.hist(brexit_age['age'])
(...)
{kind=link}
{kind=link}
It’s very boring to keep typing matplotlib.pyplot, so we can give it a
shorter name:
>>> # Set the name "plt" to point to the "matplotlib.pyplot" module
>>> plt = matplotlib.pyplot
>>> type(plt)
<class 'module'>
Now we can be more concise:
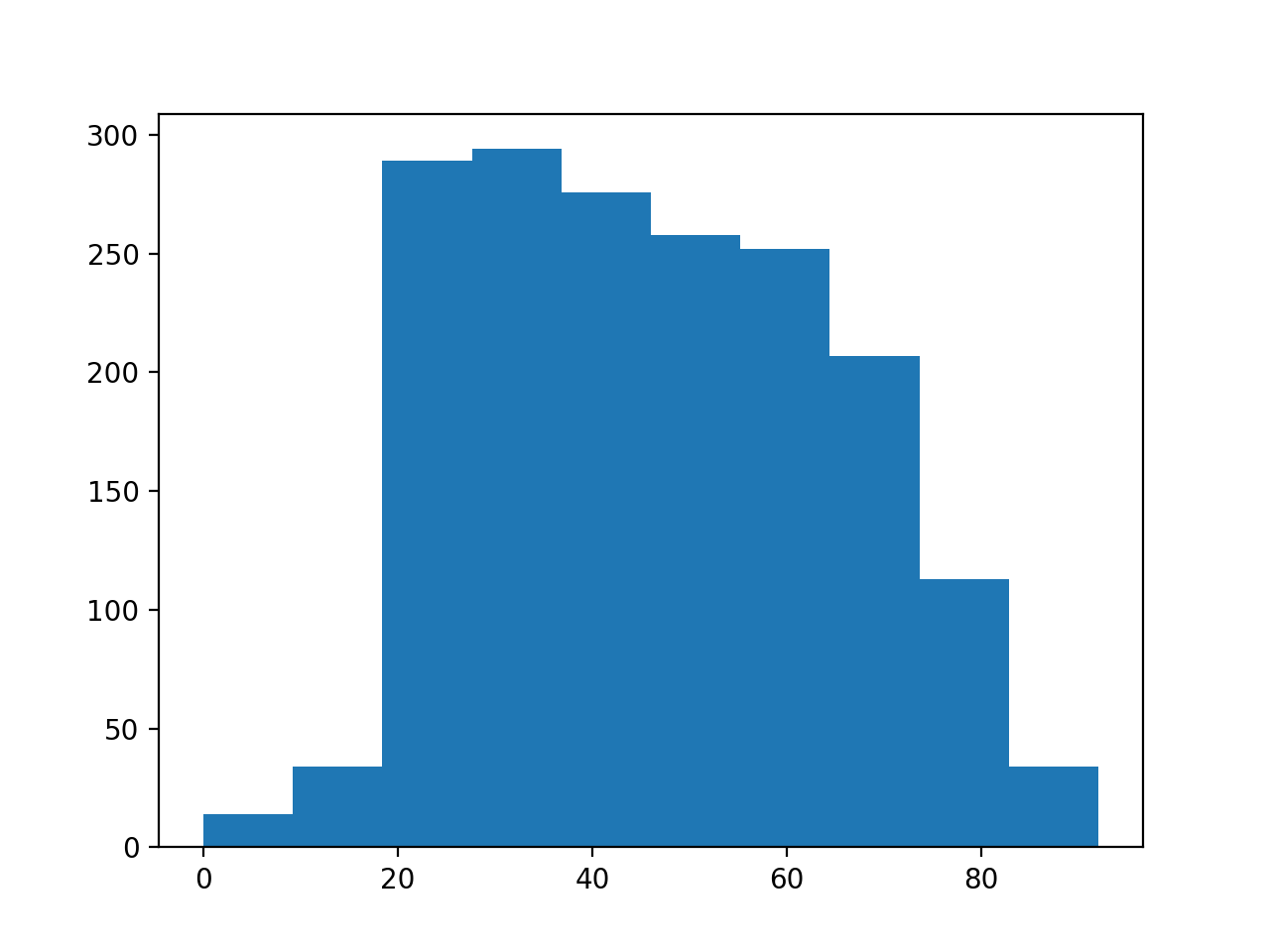
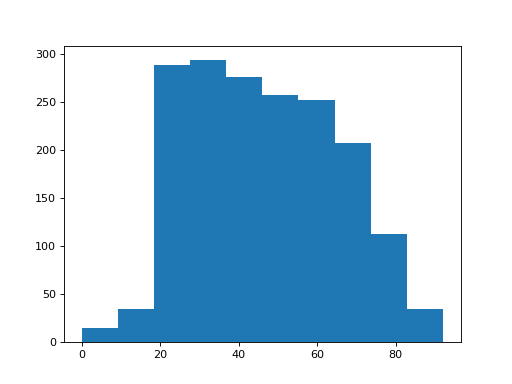
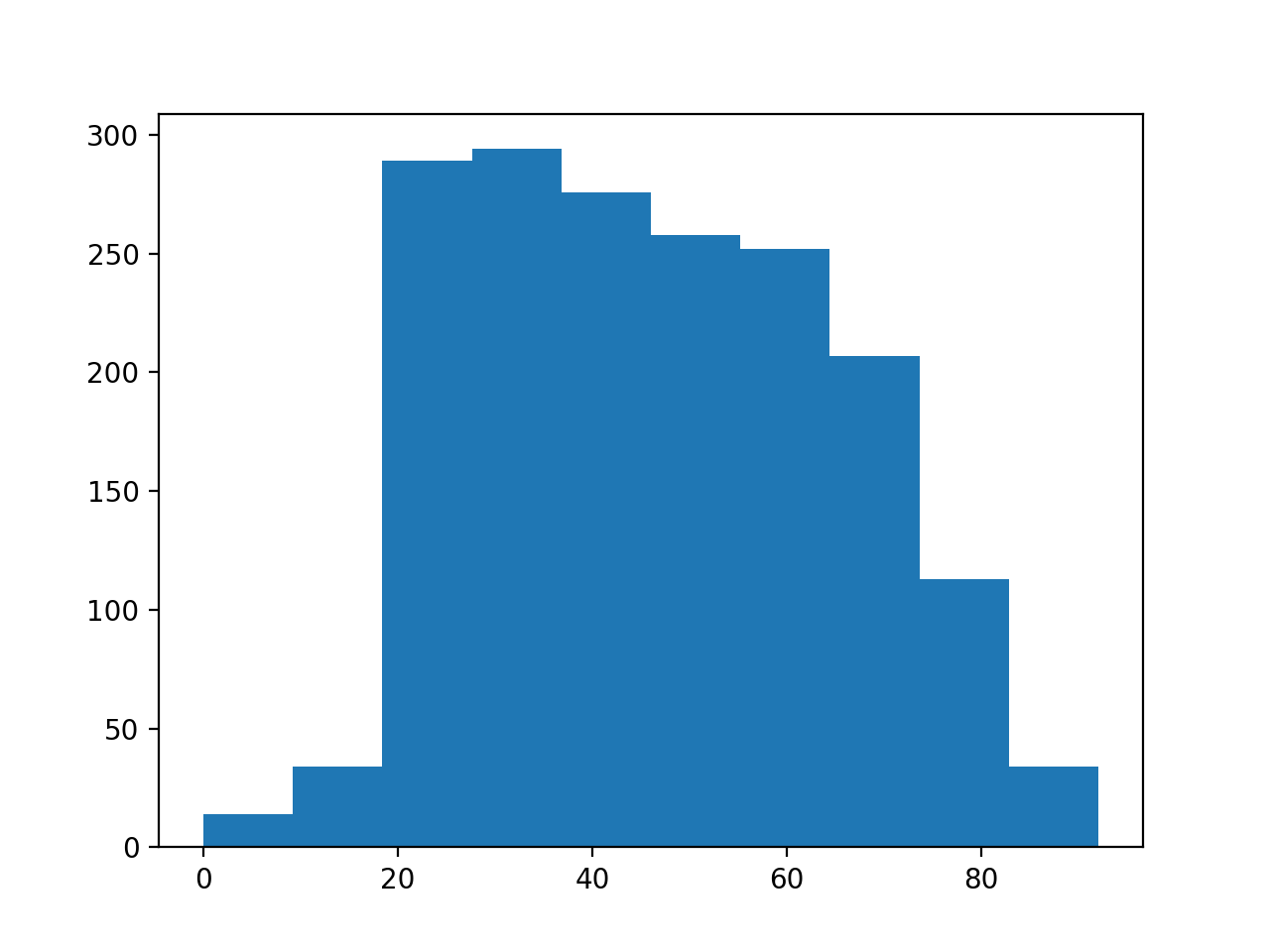
>>> plt.hist(brexit_age['age'])
(...)
{kind=link}
{kind=link}
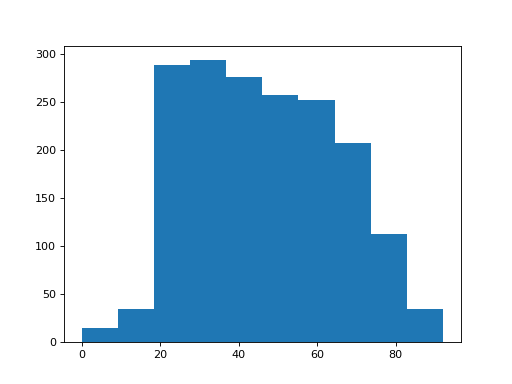
There appear to be a few subjects with age of 0.
It looks as if the survey coders are using the value 0 to mean that the person did not state their age. We will have to clean that up. We do that by selecting the cases that have ages not equal to 0.
First we get the age column into its own variable.
>>> age_column = brexit_age['age']
>>> age_column
0 37
1 55
2 71
3 37
4 42
5 0
...
1770 25
Name: age, Length: 1771, dtype: int64
This variable is of type Series:
>>> type(age_column)
<class 'pandas.core.series.Series'>
The Series represents the column from the data frame. Like the data
frame, it has row (value) labels. In our case, these are just numbers from 0.
We can convert this series, to another series that has the value True when
the age is not equal to 0, and False if it is equal to 0:
>>> # Read RHS as "age_column value not equal to 0"
>>> age_not_0 = age_column != 0
>>> age_not_0
0 True
1 True
2 True
3 True
4 True
5 False
6 True
7 True
8 True
9 True
10 False
...
1770 True
Name: age, Length: 1771, dtype: bool
This is called a boolean vector, because it is a sequence of boolean
values (True or False). We can use this to select rows in the data
frame where the value is True, and throw away the rows where the value is
False. To do this, we use the loc function attached to the data
frame. It locates values:
>>> # Select rows in the data frame where the age is not equal to 0
>>> brexit_good_age = brexit_age.loc[age_not_0]
>>> brexit_good_age
age brexit
0 37 1
1 55 1
2 71 2
3 37 1
4 42 1
6 69 1
...
[1757 rows x 2 columns]
Now we want to ask what proportion of the respondents said that they voted Remain or Leave. Later we will try to work out whether the proportion is consistent with the way that the UK voted in the referendum.
First we make a new data frame that contains only the rows for people who said they voted No in the referendum (remain). Remember, from the data dictionary, that 1 is the code for a No vote:
>>> # Select the cases who say they voted No (Remain)
>>> # First, make a boolean vector, True for remain row, False otherwise.
>>> is_remain = brexit_good_age['brexit'] == 1
>>> remainers = brexit_good_age.loc[is_remain]
>>> remainers
age brexit
0 37 1
1 55 1
3 37 1
4 42 1
6 69 1
...
[774 rows x 2 columns]
Next we make a new data frame for those who claimed to vote Yes (leave) (code 2):
>>> is_leave = brexit_good_age['brexit'] == 2
>>> brexiteers = brexit_good_age.loc[is_leave]
>>> brexiteers
age brexit
2 71 2
9 60 2
17 74 2
19 61 2
20 47 2
...
[541 rows x 2 columns]
In this sample, what are the proportion of Leave voters, compared to all those
who will confess to a vote? We use the len function to get the number of
cases in each data frame:
>>> len(brexiteers)
541
Now for the proportion:
>>> len(brexiteers) / (len(brexiteers) + len(remainers))
0.4114068441064639
As we saw in Where are the Brexiteers?, the proportion of Leave voters in the referendum was 51.9%. That seems a way off. Is it too far off?
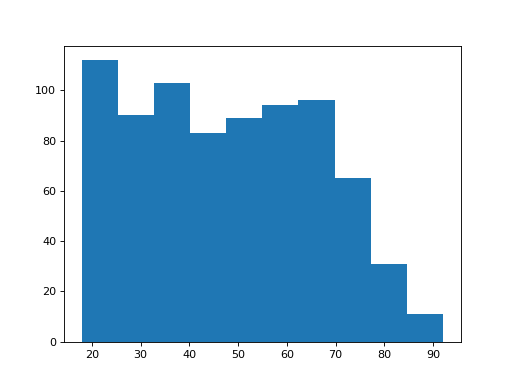
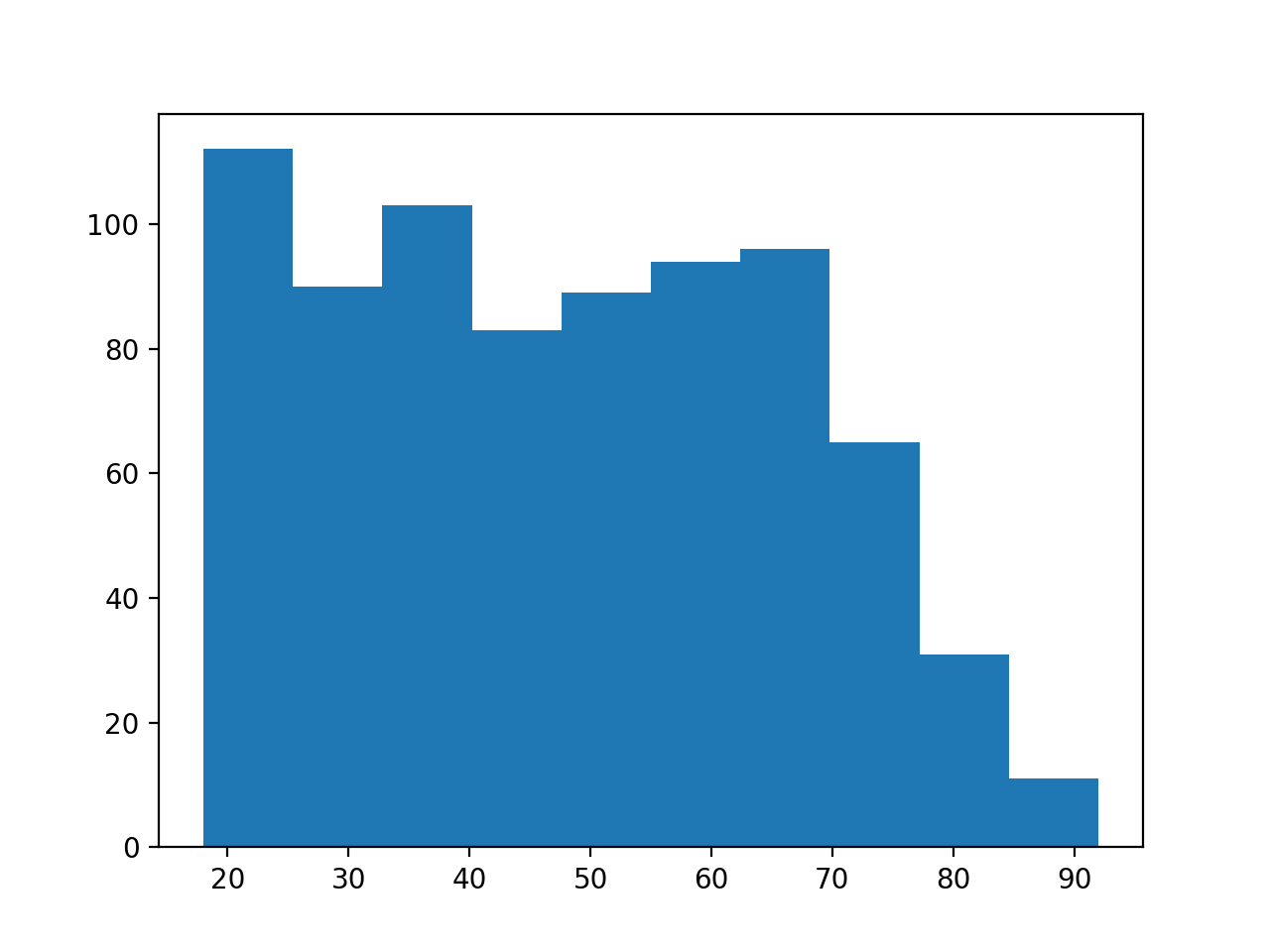
Now let’s have a look at the distribution of ages for the Remain voters:
>>> plt.hist(remainers['age'])
(...)
{kind=link}
{kind=link}
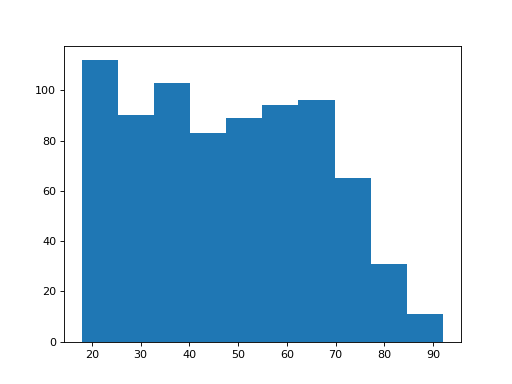
How about the ages of the Brexiteers?
>>> plt.hist(brexiteers['age'])
(...)
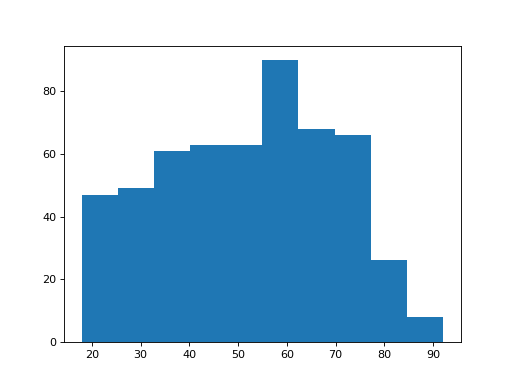{kind=link}
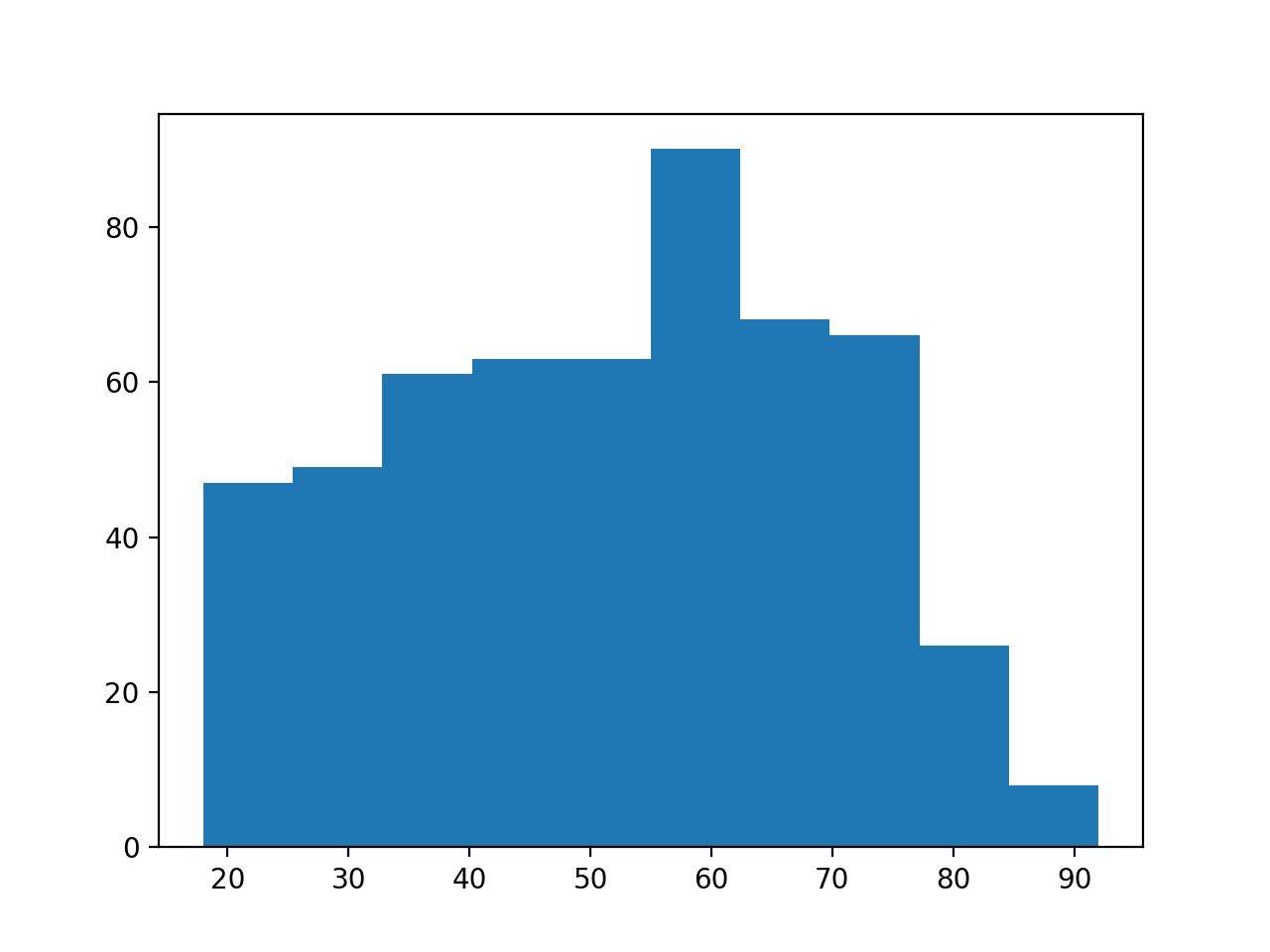{kind=link}
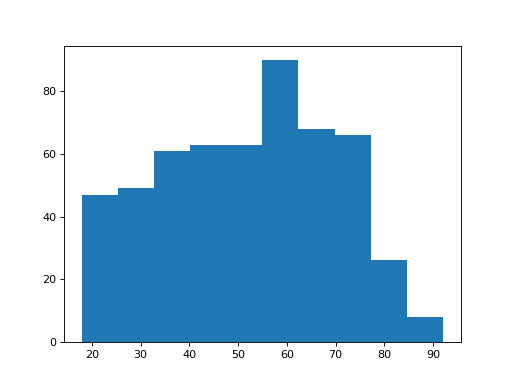
These distributions look different. But — how different are they? And how confident can we be that this difference did not come about by chance?
Last, we will save the data to use it later. First we stack the Remain and Leave cases together into one long data frame:
>>> remain_leave = pandas.concat([remainers, brexiteers])
>>> len(remain_leave)
1315
Next we save to a simple text file so we can load it later. The format is CSV, which stands for Comma Separated Values — commas separate the values within each row. In saving, we drop the index from the data frame, which just contains the case numbers:
>>> remain_leave.to_csv('remain_leave.csv', index=False)
To be safe, we check we can load back that file:
>>> remain_leave_reloaded = pandas.read_csv('remain_leave.csv')
>>> remain_leave_reloaded
age brexit
0 37 1
1 55 1
2 37 1
3 42 1
4 69 1
5 20 1
...
[1315 rows x 2 columns]